Flows
What is a Flow?
A flow is a message processing pipeline that acts as the integration layer between systems. When deployed, the flow exposes an inbound endpoint that can receive messages, transform them, and deliver them to other endpoints. In its simplest form, a flow could be a RESTful API that relays incoming data to another RESTful API, but the flow configuration process allows for much more complex data transactions.
Flow Configurations
Flows are created by writing a flow specification that the flow-server will then turn into a message processing pipeline, where messages arrive on a protocol specified by the inbound endpoint. There are many configuration options to take into account when writing a flow specification. The three main categories that make up a flow specification are processors, message flow control, and reliability.
Processors
Processors represent the sequential journey, or flow, of a message. Starting from the inbound endpoint, the message is passed through a chain of processors that either manipulate the data internally or establish a connector to an external/outbound service before passing the result on to the next step.
For instance, a flow might establish a SOAP API endpoint to receive XML. A processor can be added to transform the source’s XML to a specific JSON format. An additional processor could be added to send the newly formatted JSON to a different REST API on another server. The result of the last processor is sent back to the source to determine if the overall flow was successful or not.
Utilihive includes many pre-built processors to receive, send, transform, parse, convert, and/or compress data.
Integration connectors are also possible by way of these processors.
For example, a flow can consume messages from a Kafka cluster simply by configuring the receiveFromKafka processor, or it can publish to a Google Cloud Pub/Sub topic with the sendToGooglePubSub processor.
For a complete list of supported processors, check out the Flow Processors Index.
Message Flow Control
When a message is received by the server, it is immediately persisted in reliable storage. Unconfirmed messages (also called in-flight messages) refer to messages that have been persisted and then sent to the corresponding flow for processing but have not yet received a response. The number of concurrent in-flight messages can be configured as part of the flow specification.
If the in-flight message limit is reached, the server will keep any additional messages in memory until a slot becomes available again in the flow itself. The number of messages to buffer in memory can be configured in the flow spec.
If the buffer limit is reached, messages can still be temporarily persisted in a stash. Messages in the stash will move to the buffer as soon as memory is freed up. The number of messages to allow in the stash can be configured in the flow spec. Messages that exceed this limit will be rejected and send back an error.
Reliability
The server operates on an "at least once" principle. This means messages that failed at any point in the pipeline can be tried again before they are rejected. A redelivery strategy can be added to a flow spec to specify how many times to attempt redelivery and how often to wait in between attempts.
If redelivery fails altogether, the error and its related content can still be captured. These failed messages are called dead letters and can be logged directly to the server or sent to another flow specifically designed for error handling.
Example Use Cases
Single Flow
Let’s say user accounts are being moved to a separate service. We also want to upload a user’s avatar to an AWS S3 bucket during the account creation process. We could create a flow where the inbound endpoint (the source) is a REST API. The next step in the pipeline could be the storage bucket writer with the final processor being the REST API of the actual account service.
Visually, this flow would look like the following:

Note that the connectors needed for such a flow can easily be implemented with the help of Utilihive’s writeToAwsS3 and restRequest processors.
Multiple Flows
For this example, consider needing to consolidate data from several weather services. The caveat is that some of these services send XML while others send CSV files. The data from both cases will need to be converted to JSON before reaching their final destination (a database). We can accomplish this with three flows. The first two will act as inbound endpoints that will distribute their results to a third, shared flow (i.e., a handoff flow).
Visually, this setup would look like the following:
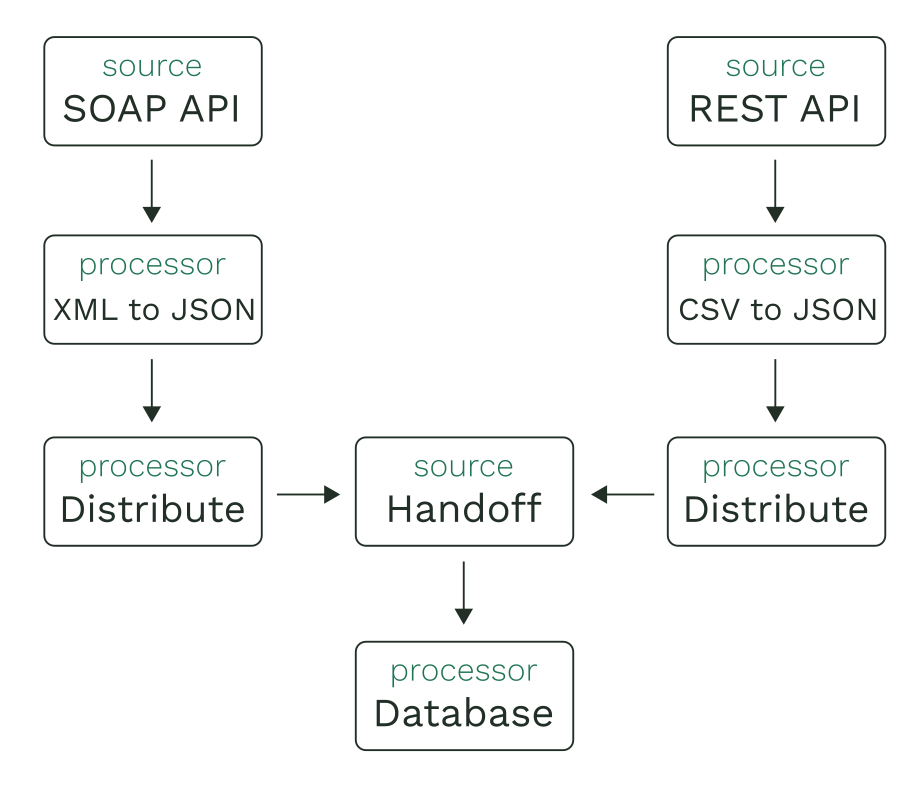
We could also add a dead letter strategy to the shared flow to capture when writing to the database fails, thus leveraging a flow’s inherent reliability.